|
I am a third-year Ph.D. student (2021 - 2025*) at Johns Hopkins University , advised by Prof. Vishal Patel , where I work on compute vision and computational photography. I got my M.Phil degree (2019 - 2021) at The Chinese University of Hong Kong, Shenzhen, advised by Prof. Rui Huang. I am open to full-time job opportunities starting early in 2025. I am a Research Intern at Google Research (Jun 2023 - Now).
I previously interned at: Adobe Research CV / Email / Google Scholar / Github / Photography |

|
 /
/
 /
/
|
My research interest mainly focuses on degraded images restoration as well as its applicatoin in high-level vision. Representative papers are highlighted. |

|
, CVPR 2024 Project Page / arXiv Faster conditional diffusion that produces high-quality images with 1-4 sampling steps. |
|
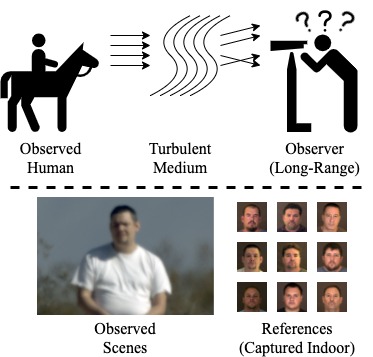
Kangfu Mei, Vishal M. Patel IEEE Journal of Selected Topics in Signal Processing, 2023 [IF: 7.695] arXiv The first turbulence mitigation algorithm that can clearly recover face images captured in a range of 300 meters long. |


|
Kangfu Mei, Vishal M. Patel, AAAI, 2023 Oral Presentation Project Page / arXiv Video Generation Diffusion Models By Using Implicit Motiion Condition. |

|
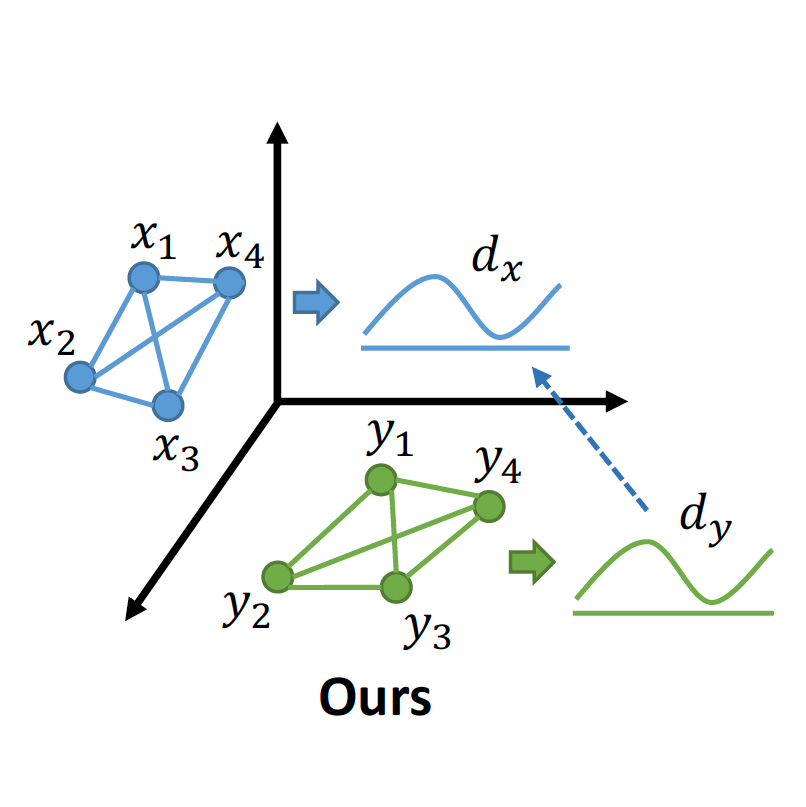
Kangfu Mei, Vishal M. Patel, Rui Huang ECCV, 2022 Project Page / arXiv / poster A New General Plug-and-play Component For Denoising |
|
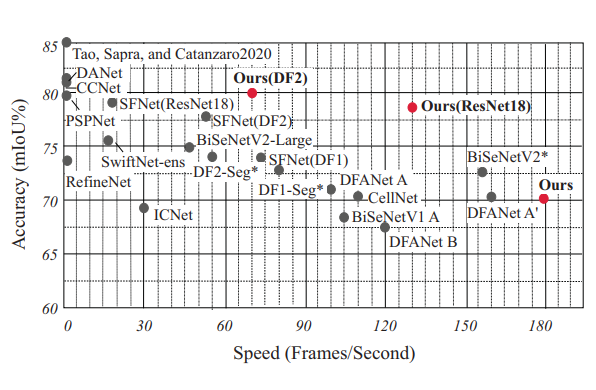
Qi Song, Kangfu Mei, Rui Huang AAAI, 2021 code / arXiv Two novel Strip Attention Module (SAM) and Attention Fusion Module (AFM) are proposed for enhancing the accuracy of semantic segmentation networks with limited computational complexity increasing. , espcically the scenes contains vertical strip areas |


|
Juncheng Li, Faming Fang, Kangfu Mei, Guixu Zhang ECCV, 2018 code / bibtex Introduce a novel multi-scale residual network for recovering the high-quality image from low-resolution. |
|
Reviewer for CVPR, ICCV, ECCV, WACV, ICPR Reviewer of International Journal of Computer Vision (IJCV) Reviewer of IEEE Transactions on Image Processing (TIP) Reviewer of IEEE Transactions on Multimedia (TMM) Reviewer of IEEE Transactions on Circuits and Systems for Video Technology (TCSVT) Reviewer of Computer Vision and Image Understanding (CVIU) |
|
AIM2019 Mobile Raw to DSLR RGB Image Mapping Challenge (ICCV2019 Workshop): Top 1 Alibaba Youku Video Enhancement and Super-Resolution Challenge 2019: Top 4 NTIRE2018 Image Dehazing Challenge (CVPR2018 Workshop): Honorable Mention Award & Top 6 University Computer Software Programming Challenge 2018 in The Pearl River Delta: Gold Award & Best innovative Award |