VIDM: Video Implicit Diffusion Model AAAI 2023
-
Kangfu Mei
JHU -
Vishal M. Patel
JHU
Abstract
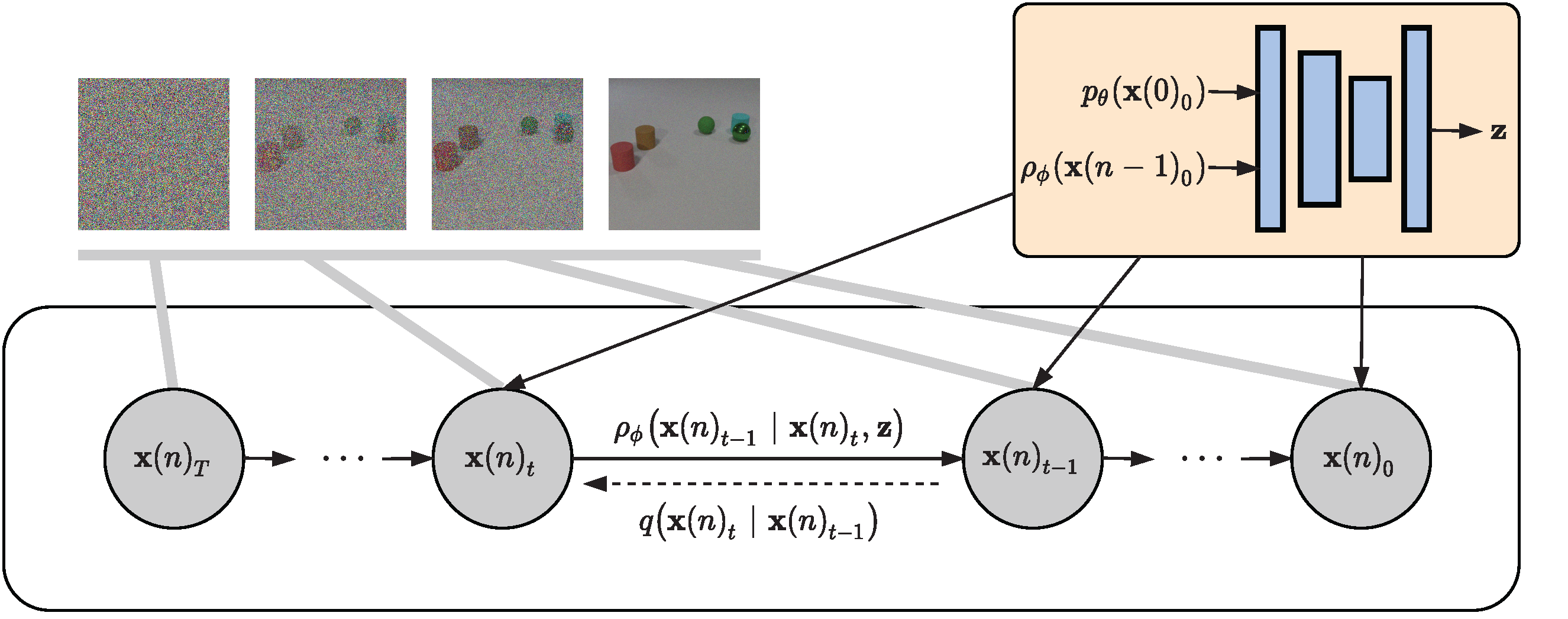
Diffusion models have emerged as a powerful generative method for synthesizing high quality images. In this paper, we propose a video generation method based on diffusion models, where the effects of motion are simulated in an implicit manner, i.e. one can sample plausible video motions according to the latent feature of the nearest frames. We improve the quality of the generated videos by proposing multiple strategies such as sampling space truncation, robustness penalty, and positional group normalization. Various experiments are conducted on datasets consisting of videos with different resolutions and different number of frames and it is shown that the proposed method can outperform the state-of-the-art generative adversarial network-based methods by a significant margin in terms of FVD scores and visual quality.
Results
UCF-101



Sky Time-lapse



TaiChi-HD



CLEVRER
Scene Fixed Result Comparisons
Citation
Acknowledgements
The website template was borrowed from Mip-NeRF 360.